|
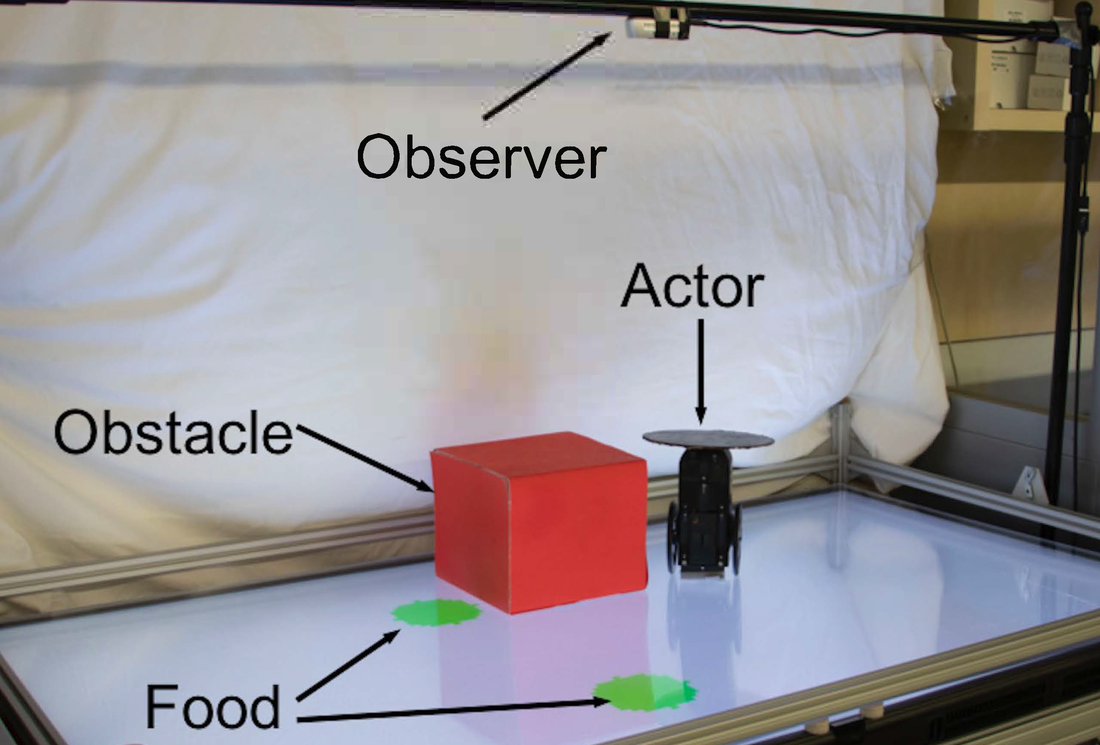
Behavior Modeling is an essential cognitive ability that underlies many aspects of human and animal social behavior, and an ability we would like to endow robots. Most studies of machine behavior modelling, however, rely on symbolic or selected parametric sensory inputs and built-in knowledge relevant to a given task. Here, we propose that an observer can model the behavior of an actor through visual processing alone, without any prior symbolic information and assumptions about relevant inputs. To test this hypothesis, we designed a non-verbal non-symbolic robotic experiment in which an observer must visualize future plans of an actor robot, based only on an image depicting the initial scene of the actor robot. We found that an AI-observer is able to visualize the future plans of the actor with 98.5% success across four different activities, even when the activity is not known a-priori. We hypothesize that such visual behavior modeling is an essential cognitive ability that will allow machines to understand and coordinate with surrounding agents, while sidestepping the notorious symbol grounding problem. Through a false-belief test, we suggest that this approach may be a precursor to Theory of Mind, one of the distinguishing hallmarks of primate social cognition.
|
|
learn more |
Source Code: github.com/BoyuanChen/visual_behavior_modeling
Columbia Magzine: story Columbia Engineering: story |
Project participants |
Boyuan Chen, Carl Vondrick, Hod Lipson
|
Related Publications |
