|
|

Close your eyes and try to imagine how your own body would move if you were to take some action, such as stretch your arms forward or take a step backward. Somewhere inside our brain we have a notion of self, a mental model of our body, something that informs us what volume of our immediate surroundings we occupy, and how that volume changes as we move.
Our body image -- how we imagine ourselves -- is an important piece of information that determines how we function in the world. When you get dressed in the morning or play ball in the afternoon, your brain is constantly planning ahead so that you can reach your goal without bumping, tripping, or falling over. |

We humans acquire our body-model as infants, and robots are following suit. In this project we have created a robot that -- for the first time -- is able to learn a model of its entire body from scratch, without any human assistance. We demonstrated how the robot then used its self-model to plan motion, reach goals, and avoid obstacles in a variety of situations. It even automatically recognized and then compensated for damage to its body.
To do this, we placed a robotic arm inside a circle of five streaming video cameras. The robot watched itself through the cameras as it undulated freely. Like an infant exploring itself for the first time in a hall of mirrors, the robot wiggled and contorted to learn how exactly its body moved in response to various motor commands. After about three hours, the robot stopped. Its internal deep neural network had finished learning the relationship between the robot’s motor actions and the volume it occupied in its environment.
To do this, we placed a robotic arm inside a circle of five streaming video cameras. The robot watched itself through the cameras as it undulated freely. Like an infant exploring itself for the first time in a hall of mirrors, the robot wiggled and contorted to learn how exactly its body moved in response to various motor commands. After about three hours, the robot stopped. Its internal deep neural network had finished learning the relationship between the robot’s motor actions and the volume it occupied in its environment.

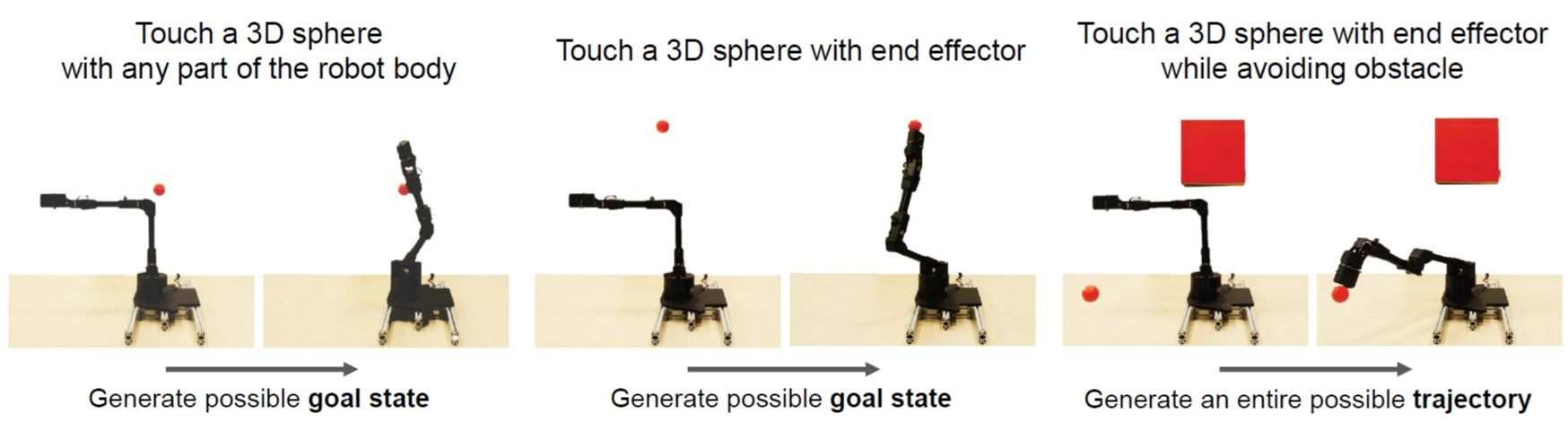
We were really curious to see how the robot imagined itself. But you can’t just peek into a neural network, it’s a black box. However, struggling with various visualization techniques, the self-image gradually emerged. It was a sort of gently flickering cloud that appeared to engulf the robot’s three-dimensional body. As the robot moved, the flickering cloud gently followed it. The robot’s self-model was accurate to about 1% of its workspace.
The ability of robots to model themselves without being assisted by engineers is important for many reasons: Not only does it save labor, but it also allows the robot to keep up with its own wear-and-tear, and even detect and compensate for damage. This ability is important as we need autonomous systems to be more self-reliant: A factory robot, for instance, could detect that something isn’t moving right, and compensate or call for assistance.
The work is part of our decades-long quest to find ways to grant robots some form of self-awareness. Self-modeling is a primitive form of self-awareness. If a robot, animal, or human, has an accurate self-model, it can function better in the world, it can make better decisions, and it has an evolutionary advantage. Learn more about the history of our self-awareness projects is the video below.
The ability of robots to model themselves without being assisted by engineers is important for many reasons: Not only does it save labor, but it also allows the robot to keep up with its own wear-and-tear, and even detect and compensate for damage. This ability is important as we need autonomous systems to be more self-reliant: A factory robot, for instance, could detect that something isn’t moving right, and compensate or call for assistance.
The work is part of our decades-long quest to find ways to grant robots some form of self-awareness. Self-modeling is a primitive form of self-awareness. If a robot, animal, or human, has an accurate self-model, it can function better in the world, it can make better decisions, and it has an evolutionary advantage. Learn more about the history of our self-awareness projects is the video below.
Videos
|
High-level Overview
|
Technical Overview
|
Overview of our robot self-awareness projects
|
Technical ABSTRACT
Internal computational models of physical bodies are fundamental to the ability of robots and animals alike to plan and control their actions. These “self-models” allow robots to consider outcomes of multiple possible future actions, without trying them out in physical reality. Recent progress in fully data-driven self-modeling has enabled machines to learn their own forward kinematics directly from task-agnostic interaction data. However, forward-kinematics models can only predict limited aspects of the morphology, such as the position of end effectors or velocity of joints and masses. A key challenge is to model the entire morphology and kinematics, without prior knowledge of what aspects of the morphology will be relevant to future tasks. Here, we propose that instead of directly modeling forward-kinematics, a more useful form of self-modeling is one that could answer space occupancy queries, conditioned on the robot’s state. Such query-driven self-models are continuous in the spatial domain, memory efficient, fully differentiable, kinematic aware and can be used across a broader range of tasks. In physical experiments, we demonstrate how a visual self-model is accurate to about one percent of the workspace, enabling the robot to perform various motion planning and control tasks. Visual self-modeling can also allow the robot to detect, localize and recover from real-world damage, leading to improved machine resiliency.
learn more |
Source Code: GitHub Visual Self Modeling
Columbia Press: TBD |
Press |
|
Project participants |
Boyuan Chen, Robert Kwiatkowski, Carl Vondrick, Hod Lipson
|
Related Publications |
Chen B, Kwiatkowski R, Vondrick C, Lipson H (2022) “Full-Body Visual Self-Modeling of Robot Morphologies.” Science Robotics Vol. 7, eabn1944
|
